
In 2025, the vendors in our dataset experienced 9,859 vendor-days of service disruption. That's 236,000 hours where at least one vendor service was degraded or offline, up significantly from the year before.
We wanted to understand what drove that number, so we dug into the data. Clarative tracks over 3,400 vendors across incident monitoring, synthetic endpoint monitoring, adverse media, and public regulatory filings. For this report, we analyzed 76,000 incidents, 1.4 billion synthetic monitoring pings across 28,000 endpoints, roughly 2,000 adverse media articles, and hundreds of SEC risk factor filings. The data covers January 2024 through February 2026.
Here's what the vendor risk picture looks like heading into 2026, and what it means for how organizations should think about vendor due diligence and ongoing risk monitoring.
Across a consistent cohort of 132 vendors we've tracked since early 2024, incidents nearly doubled year-over-year. Total reported incidents went from 14,407 in 2024 to 28,765 in 2025. CRITICAL incidents increased 244%. MAJOR incidents increased 151%.
The raw increase tells part of the story and the severity mix tells the rest. In 2024, CRITICAL and MAJOR incidents made up 28% of all reported incidents while in 2025, that share rose to 38%. Vendors are experiencing more incidents and a higher proportion of those incidents are serious.
Part of what's driving the increase is the expanding footprint of vendor platforms themselves. Vendors are adding services, regions, and product lines, and more surface area means more places that things can break. However, the severity shift is independent of the volume growth. Even accounting for platform expansion, the mix is trending toward more impactful events.
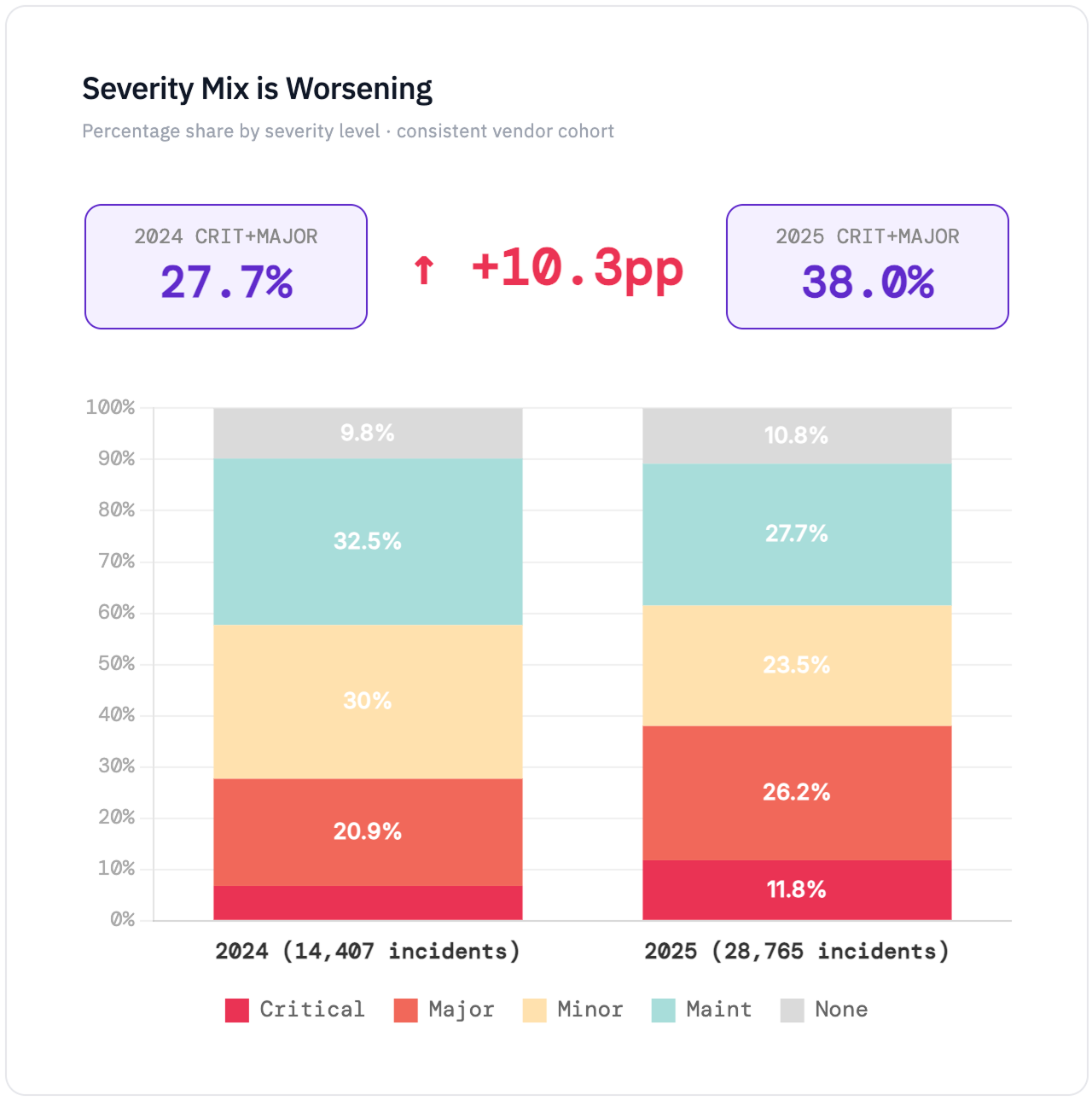
Percentage share by severity level · consistent vendor cohort
These incident numbers come from vendor-reported status page data. Clarative also independently monitors 28,000+ vendor endpoints every five minutes, generating 1.4 billion observed data points since launch. That synthetic monitoring data shows that APIs are the least reliable endpoint type at 99.91% measured uptime, while authentication endpoints are the most reliable at 99.998%. Incident reports and synthetic monitoring tell different parts of the same story. Combining them with adverse media and regulatory filings builds a more complete risk picture than any single source provides alone.
A vendor's incident history, severity trends, and independently measured uptime are direct inputs to understanding their operational risk profile. This kind of data should inform both onboarding assessments and annual reassessments. It also serves as the continuous signal that tells you when a vendor warrants a closer look between scheduled review cycles.
We used AI-assisted classification to categorize the root causes of 800 CRITICAL and MAJOR incidents from the past three months. The results give a picture of where vendor failures actually originate.
Software bugs account for 31% of classifiable major incidents. Code defects, regressions, and failed deployments remain the single largest cause of serious vendor outages. Third-party and operational dependencies are close behind at 27%, infrastructure failures account for 21%, while capacity and scaling issues, DNS and networking problems, configuration errors, and AI-related failures make up the remaining 21%.
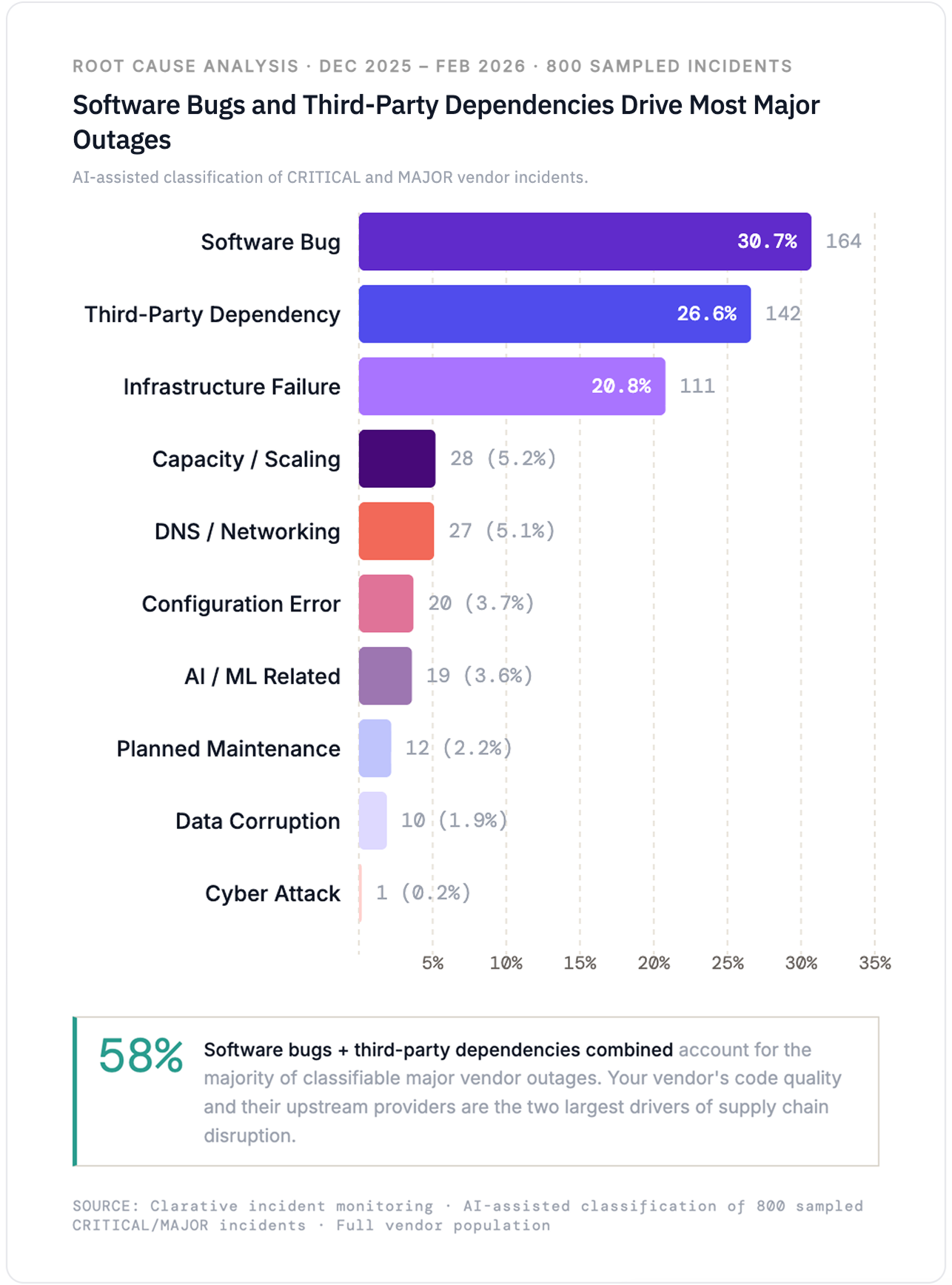
AI-assisted classification of CRITICAL and MAJOR vendor incidents.
The third-party dependency number deserves attention. On October 20, 2025, a DNS race condition in AWS's US-EAST-1 region triggered a 15-hour outage that took down services at Netflix, Slack, Atlassian, Snapchat, Coinbase, Starbucks, and hundreds of other companies simultaneously. A month later, Cloudflare experienced two separate global outages within weeks of each other, disrupting access to services that depend on its CDN and security infrastructure. Your vendor's infrastructure dependencies are your infrastructure dependencies.
We examined the infrastructure providers behind 1,800+ critical endpoints, covering APIs, web applications, and authentication services.
51% of vendors run critical infrastructure on AWS and 34% use Cloudflare. The top four providers (AWS, Cloudflare, Google Cloud, and Microsoft Azure) account for over 80% of the vendor ecosystem, and 75% of vendors rely on a single infrastructure provider for their critical endpoints, with no multi-cloud failover.
This creates correlated risk across supply chain portfolios. An AWS outage doesn't just affect one vendor. It can potentially impact over half the vendors an organization depends on. That risk is largely invisible unless you're specifically mapping infrastructure dependencies as part of your vendor due diligence process.
Operational performance and infrastructure dependencies should be part of vendor risk assessments. Understanding how a vendor's reliability has trended over time, what's causing their outages, and who they depend on gives you a clearer picture of the risk they bring into your environment.
We analyzed hundreds of SEC 10-K and 10-Q filings across public technology companies filed between 2024 and early 2026. The risk themes vendors disclose to regulators have shifted meaningfully over that period.
Business continuity went from appearing in 70% of filings to 100%. Every recent filer now explicitly flags service reliability and disaster recovery as a material risk. Third-party dependency mentions rose from 48% to 75% and cybersecurity mentions climbed from 30% to 50%.
The fastest-growing category is AI risk, which tripled from 22% to 50% of filings in eighteen months. The language in these disclosures has evolved. Early filings referenced generic "technology changes including artificial intelligence”, while recent filings call out specific concerns AI models that are biased, inaccurate, or insufficient; regulatory compliance across multiple jurisdictions; ethical and social consequences of AI deployment; and reputational and legal liability from irresponsible AI use. PagerDuty's filings, for example, flag risks from AI model bias, inaccuracy, and regulatory compliance across multiple jurisdictions. Tenable describes risks around deploying generative AI and agentic AI solutions, including data rights issues, privacy concerns, and the risk of AI agents taking actions based on flawed outputs.
Adverse media coverage reinforces the SEC signal. AI-related risk accounts for 8.5% of negative vendor news coverage for the past two quarters and is trending upward. In the past few months alone, an AWS AI coding agent autonomously caused a 13-hour service outage, OpenAI faced scrutiny after flagging a user's threatening messages but not alerting law enforcement before a shooting, and state-backed threat actors were found using Google's Gemini AI to plan cyberattacks.
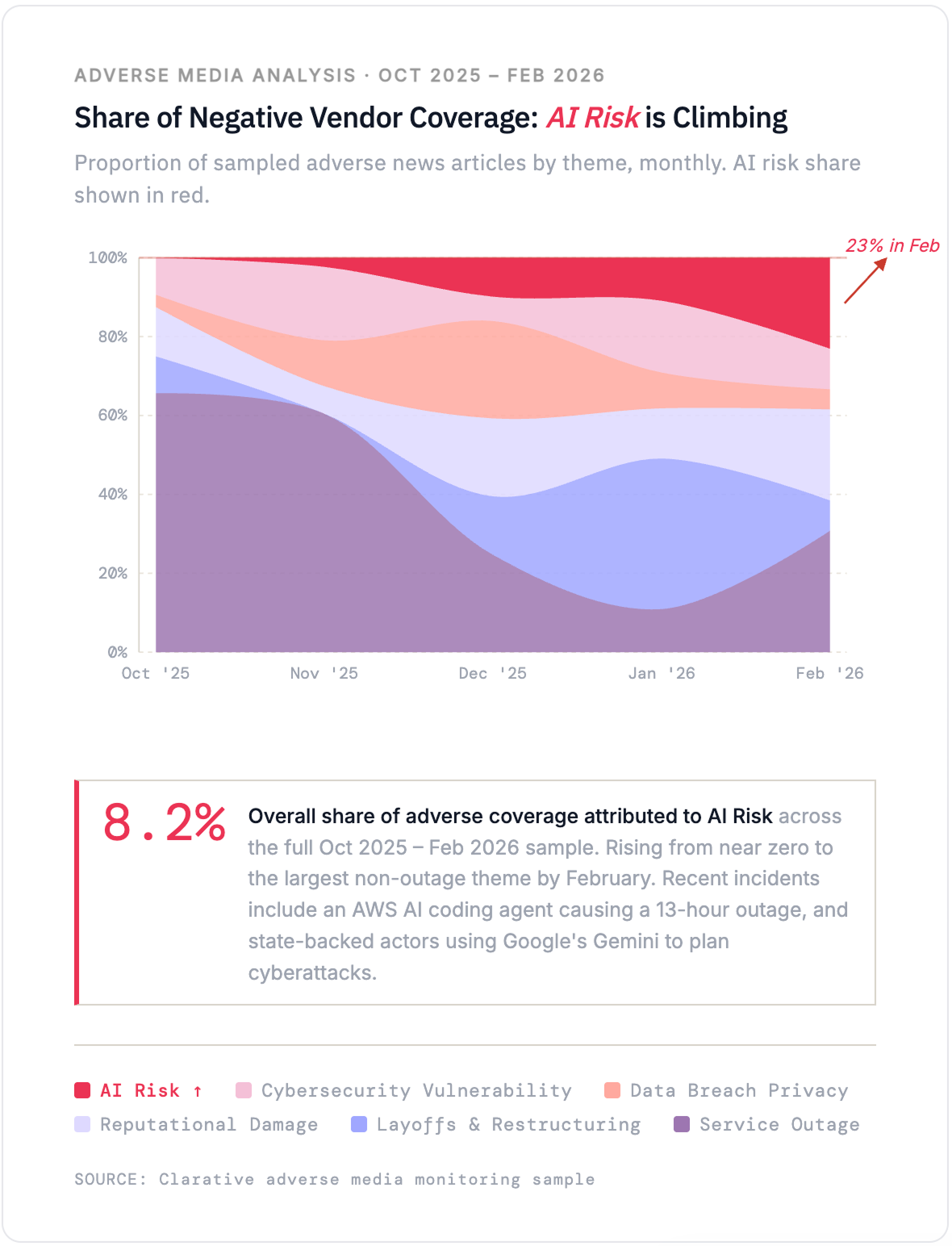
Proportion of sampled adverse news articles by theme, monthly. AI risk share shown in red.
On vendor status pages, AI-related root causes still account for a relatively small share of reported incidents at about 3.6%, but we expect that number will grow as vendors embed AI more deeply into their products and internal operations.
AI governance, third-party dependencies, and business continuity planning should all be part of how you evaluate vendors. For AI specifically, that means understanding how vendors test and validate AI outputs, whether they have rollback procedures for autonomous operations, and how they're preparing for regulatory frameworks like the EU AI Act. SEC filings are a useful signal across all three areas. What vendors disclose to regulators reflects what they consider real risks to their own business, and those disclosures become risks for your business.
Three takeaways from the data.
Connect point-in-time assessments with continuous monitoring. Ongoing signals like incident trends, adverse media, and synthetic uptime data should inform when a vendor needs a deeper reassessment and where to focus it. A continuous picture of inherent risk makes periodic assessments more targeted and efficient. AI can help you go deeper on the vendors that need it most, without scaling headcount or budget.
Incorporate AI risk into your vendor risk assessments. More and more public tech companies now flag AI as a material risk in their SEC filings. That's a strong signal that AI governance belongs in your evaluation criteria. Assess vendors on their technical AI governance practices and their regulatory preparedness as frameworks like the EU AI Act take effect.
Build a multi-source view of vendor risk. Incident data, synthetic monitoring, adverse media, and regulatory filings each reveal different dimensions of risk. Organizations with the strongest vendor risk programs connect these signals into a single picture that informs both due diligence and ongoing monitoring.
Clarative was built to close the loop on all three. We continuously monitor vendor incidents, synthetic endpoint uptime, adverse media, security breaches, and regulatory filings to maintain a real-time picture of inherent risk across your portfolio. When that picture changes, our AI runs targeted due diligence using Clarative's proprietary data, public data, and vendor-submitted documentation. Clarative includes ready-made playbooks for the risk areas covered in this report: BC/DR and operational resilience (DORA), AI risk (OWASP AI frameworks, EU AI Act), and subcontractor risk management, with automated intake and registry reporting for DORA, OSFI E-21, OCC Guidelines, and more. The result is a vendor risk program where continuous monitoring and point-in-time assessments reinforce each other, covering the full lifecycle from onboarding through ongoing oversight.
This analysis was powered by the Clarative vendor intelligence platform. To see what these insights look like for your vendor portfolio, please reach out.